As I was setting up a training environment today I encountered a “gotcha” that is worth mentioning when you are logged in as a new user in an AWS CodeStar project.
I logged in using an IAM user with the “AWSCodeStarFullAccess” role and was able to access the AWS CodeStar console just fine, seeing the banner telling me to connect to my project, I obediently followed the “Connect Tools” button and saw that my own personal git repo was still being constructed.
An hour later (don’t worry I wasn’t sitting around doing nothing for the hour) I noticed that it still had not completed, and after some playing around I realised what I had done wrong – it was a bit of a Duh! moment.
IAM access isn’t enough, you need to add your IAM Users to your CodeStar Project!
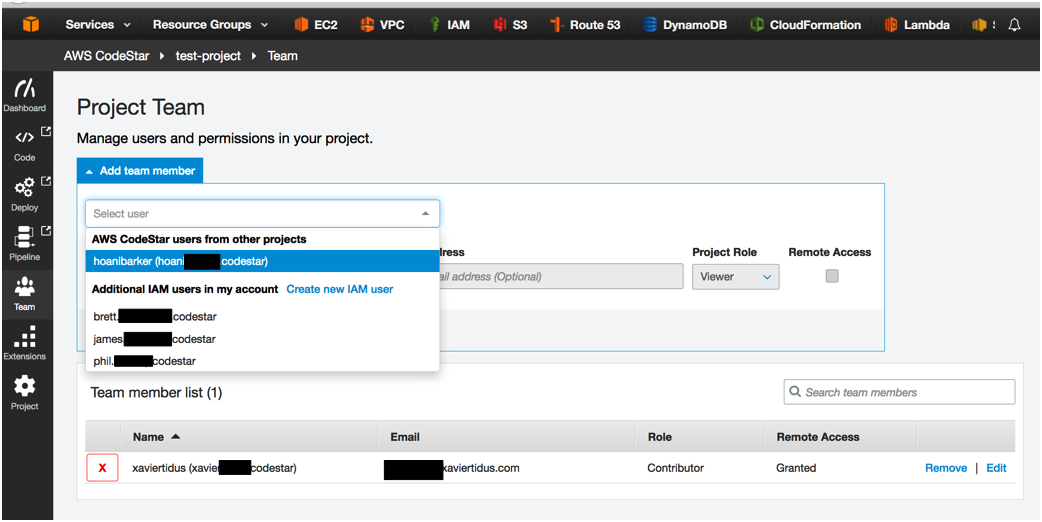
So I logged into the AWS Console using an IAM user with CodeStar Project Admin rights, clicked on “Team” in the right hand menu and added the missing user to the CodeStar Project.
selecting-user-from-list
Then I switched back to the other browser which my contributor IAM user was still logged into and within seconds the Git Repo was ready.
repository-is-now-created
I guess that this process will be something that is improved over time, but was worth mentioning.
I hope this helps someone out, if so don’t be afraid to say hi in the comments below!
Today I will be writing about a problem that has occurred a few times in my day job that seems to trip a lot of people up.
The disappearance of additional storage drives in an AWS instance running Windows Server 2012 R2.
Servers at risk
Windows Servers originally built from a AWS Windows Server 2012 R2 AMI prior to September 10th 2014.
Windows Servers built from a user built AMI that was originally created from an AWS Windows Server 2012 R2 AMI prior to September 10th 2014
Symptoms
Typical list of symptoms of this issue include:
Sudden disappearance of additional drive/s after a shutdown or reboot;
Despite the drives no longer appearing in Windows you will see the drives still attached in AWS.
Attempts to un-mount the drives and remounting them (even to new mount paths) will result in no fix.
Loss of custom IP configurations in your Ethernet adapters on the server (such as static IPs, gateway and DNS settings / values, as well as the re-enabling of ipV6 if you had turned this off previously). Note: If this happens depending on your AWS setup you may be unable to even access this server. See the “regaining access to your server” section at the end of this page.
Cause
In short the issue is caused by the “Windows scheduler plug and play clean up” and will impact any Windows Server 2012 R2 AMI release before September 10th 2014.
Fixing this is a two stage process, first we need to reinstall the XenTools drivers for the AWS server, then we will need to run a script file that AWS has published to disable the scheduled task that causes this mischief-ery.
Reinstalling the ZenTools drivers
When I originally had this problem the gentleman at AWS recommended that I reinstall the ZenTools drivers, so I will recommend the same to you now! 🙂
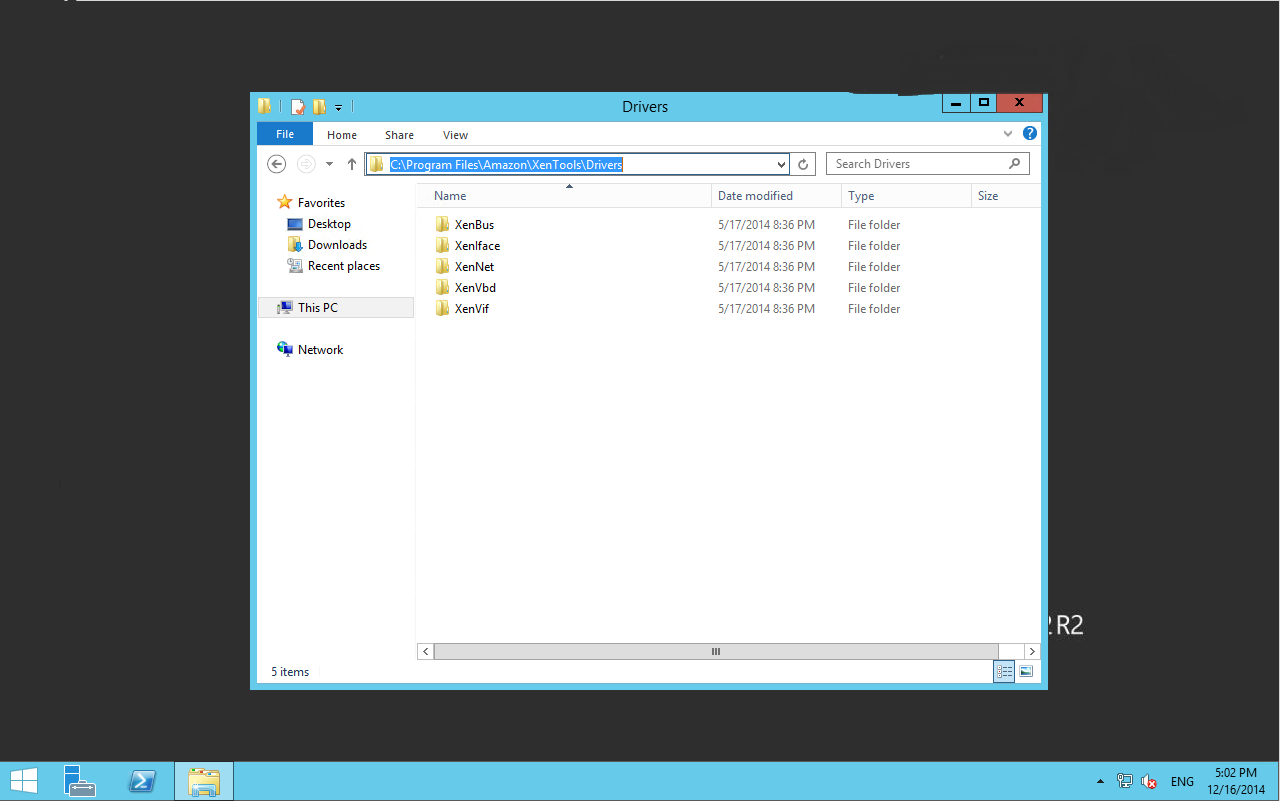
The drivers for re-installation should be located on your server at: C:\Program Files\Amazon\XenTools\Drivers\
The location for your XenTools drivers should be C:\Program Files\Amazon\XenTools\Drivers
Then make your way through the folders reinstalling the drivers below (right click the files in the list below and select “Install Driver”)
If you check now, your drives have probably re-appeared. If not don’t panic they will later, and if they have DO NOT STOP HERE, you need to do the next step as well or this could happen all over again.
Download this onto the server and extract to a folder close to the root of c:, for this example we will be placing the RemediateDriverIssue.ps1 file in the folder c:\temp Please adjust the command below as necessary to suit your situation
Start a Power Shell as “Administrator” WARNING! Do not start a Power Shell ISE to run this script! Use a regular Power Shell running as Administrator.
Execute the following command into the power shell, remembering to adjust the path to where you placed your script file as necessary:
Inspect the on screen feedback, you should be met with a success message shortly. Go ahead and close the window at this point. You’re done!
If you don’t get any success of if the script identifies that it is not suited to your situation follow the onscreen prompts. If you need help contact AWS support and advise them of this page so they know what you have attempted. Alternatively post below and maybe I can help.
You’re Done!
And that’s it! Your drives should now have reappeared and your patch / script should now be applied to prevent this from happening again. However the last thing to do is reboot the server to make sure that our fix will stick. If your server still has issues after this, post a comment below and I will try to help!
Oh and if you keep regular backups or AMIs of your servers, make sure that you create new ones of them now so you don’t have to reapply this fix again to your future instances!
Regaining access to your server after a loss of custom networking settings
This is not a fun situation to be in, however you may get lucky. Below is a list of things you can try depending on your circumstances and network configuration.
I have access to another server attached to the same VPC / Subnet
Ok this is great, here is what you can try:
Make sure that RDP is enabled on your security groups that both the server you want to be able to reach and the server you can reach are attached to.
Reboot the server that you are unable to reach (gracefully if possible) from the AWS console.
Once the server is back online, wait for the server health checks to complete.
Look at the details of that instance and locate the AWS DHCP assigned ip address
On the server you have access to, attempt to establish a RDP session to the IP Address you observed in the previous step.
Hopefully you should have established a connection to the server.
I don’t have another instance on the same VPC / Subnet, but I can create a new instance
This isn’t a bad option. Essentially all you have to do is create any old Windows server on the same VPC, then do the previous suggestion. Once complete you can delete the instance you just created. Should only cost you a couple dollars and will give you access again to the server.
I don’t have another instance on the same VPC / Subnet, and I cannot create a new instance
This isn’t too bad either, try the following:
Create a new network adapter for the server in a VPC with a security group that allows RDP.
Attach that network adapter to the server you want to be able to access.
Assign yourself a new Elastic IP and attach it to the new network adapter.
Attempt to establish a remote desktop connection to the server.
I cannot do any of the above, or the above did not work for me and I still cannot access my server
It’s time to contact AWS support unfortunately, you can also try posting below and I or someone else that trolls this site may be able to offer assistance. Don’t forget sites like Server Fault too as they are full of geniuses and always yield quick responses. Just be sure to keep the community happy by writing whilst not in a panic and in detail, and most importantly always Google first.